DFT in osnove naključnih procesov#
Domača naloga#
Naloga
Z uporabo generatorja signalov in zajemnega sistema Arduino zajemite naključni signal s parametri (srednjo vrednostjo \(m\), standardno deviacijo \(\sigma\)) iz podatkov naloge. Zajem podatkov izvedite tako, da boste pri pretvorbi zajetega signala v frekvenčno domeno dobili spekter na podanem frekvenčnem območju \([0, f_k]\) ter z ločljivostjo v frekvenčni domeni \(\Delta f\) iz podatkov naloge.
LabView program za zajem signalov lahko prenesete v obliki zip arhiva.
Pripravite kratko poročilo v okolju Jupyter Notebook (od 3 do 10 celic s kodo), v katerem naj bodo razvidni podatki naloge ter prikaz in kratek komentar naslednjih lastnosti zajetega signala:
zajeto frekvenčno območje in frekvenčna ločljivost,
ocena gostote porazdelitve verjetnosti vrednosti \(p(x)\) zajetega signala \(x(t)\),
enostranska ter dvostranska avtospektralna gostota moči, \(G_{XX}\) in \(S_{XX}\),
prvi štirje centralni statistični momenti (\(m_1\), \(m_2\), \(m_3\), \(m_4\)) zajetega signala.
Dodatek:
Ovrednotite in komentirajte stacionarnost ter ergodičnost zgoraj generiranega naključnega signala (po potrebi zajemite dodatne signale, ki jih za to potrebujete).
Numerično generirajte in komentirajte primera nestacionarnega gaussovega ter stacionarnega ne-gaussovega naključnega signala (glejte na primer pyExSi).
Poročilo oddajte v .pdf obliki (glejte navodila za oddajo domačih nalog).
Diskretna Fourierova transformacija#
Računamo Fourierovo transformacijo diskretnega signala, \(x_n = x(n\,\Delta t)\). Kadar imamo končno mnogo vzorčenih podatkov (\(N\)) in gre \(n=[0,1,\dots,N-1]\), uporabimo diskretno Fourierovo transformacijo (DFT).
Note
Diskretna Fourierova transformacija:
Velja \(X_k=X(k/(N\,\Delta t))\).
Ker je DFT periodična z \(1/\Delta t\) (\(X_k=X_{k+N}\)), je treba izračunati samo \(N\) členov.
Modul numpy.fft izračuna \(X_k\) za diskretne frekvenčne točke pri \(k \in [-N/2, \dots, 0,\dots\,N/2-1]\) (v primeru sodega števila točk \(N\)).
Primer 1
Poglejmo diskretizacijo frekvenčnega vektorja pri DFT signala, vzorčenega pri časih: \(t = [0, 1, 2, \dots, 9] s\):
t = np.arange(0, 10)
delta_t = t[1] - t[0]
n = len(t)
delta_t, n
(np.int64(1), 10)
np.fft.fftfreq(len(t), t[1]-t[0])
array([ 0. , 0.1, 0.2, 0.3, 0.4, -0.5, -0.4, -0.3, -0.2, -0.1])
np.fft.rfftfreq(len(t), t[1]-t[0])
array([0. , 0.1, 0.2, 0.3, 0.4, 0.5])
Osnove naključnih procesov#
Procese, ki jih ne moremo obravnavati kot deterministične, pogosto modeliramo kot naključne procese.
Za te je značilno, da njihovih dejanskih vrednosti v času \(x(t)\) ne moremo natančno predvideti, lahko pa z določeno verjetnostjo sklepamo o porazdelitvi njihovih vrednosti. Tako definiramo funkcijo gostote porazdelitve verjetnost, \(p(x)\), ki podaja verjetnost, da se bo v vzorcu naključne spremenljivke \(x(t)\) pojavila določena vrednost \(x\).
Lastnosti takih signalov je pogosto smiselno obravnavati v frekvenčni domeni.
Primer 2
Normalno porazdeljena naključna spremenljivka \(x\) z \(N=1000\) vzorci, srednjo vrednostjo \(\mu = 5\) in standardno deviacijo \(\sigma = 2\) predstavlja realizacijo N ponovitev naključnega dogodka.
Ocenimo prva dva centralna statistična momenta funkcije gostote verjetnosti (\(n = [1, 2]\)):
N = 1000
mu = 5
sigma = 2
x = np.random.randn(N)*sigma + mu
x_center = x - np.mean(x)
s_1 = np.mean(x_center)
s_1
np.float64(1.5987211554602254e-16)
s_2 = np.mean((x_center)**2)
s_2
np.float64(3.9406844648384176)
Bolj splošen generator naključnih vrednosti v Numpy:
rng = np.random.default_rng()
y = rng.normal(loc=mu, scale=sigma, size=N)
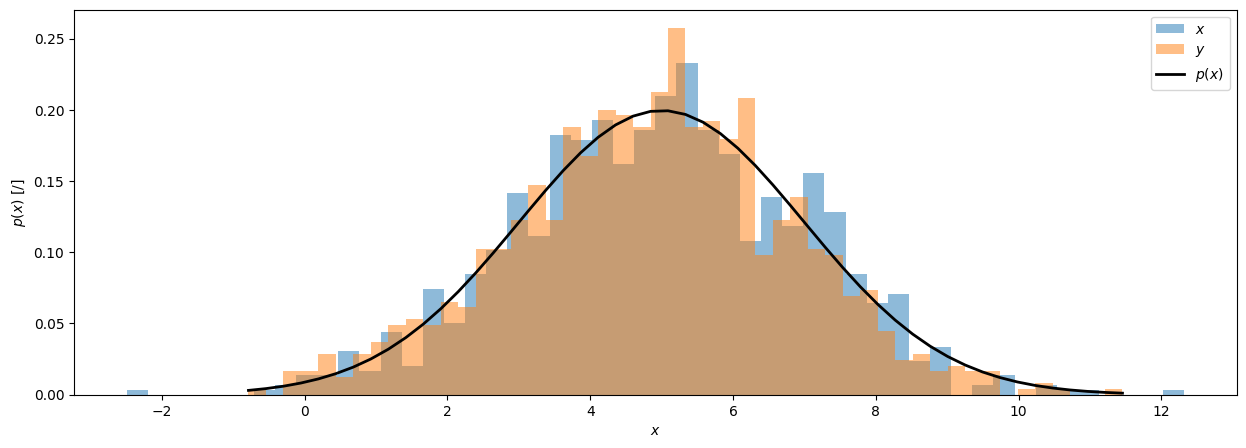
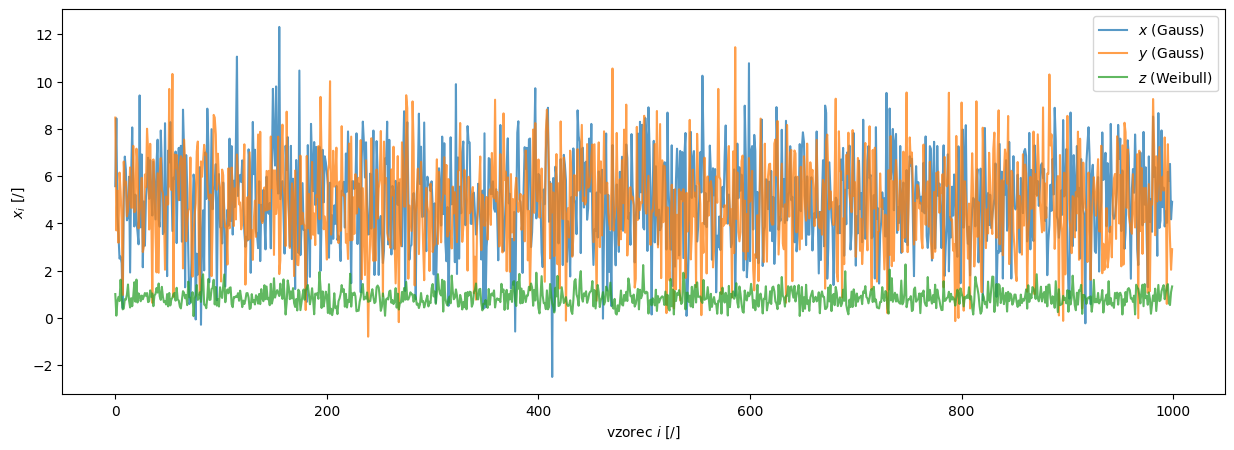
Porazdelitev verjetnosti ni nujno normalna (Gaussova):
z = rng.weibull(a=2.5, size=N)
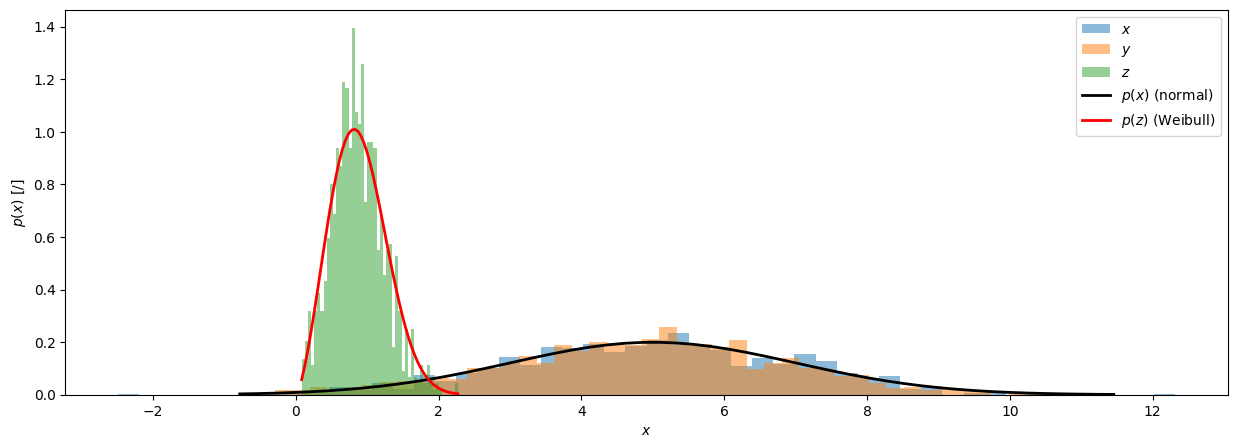
Note
Naključni proces \(x(t)\) je stacionaren, če so srednja vrednost in kovariančne funkcije procesa časovno neodvisne.
Naključni proces \(x(t)\) je ergodičen, če so statistične lastnosti nižjega reda ene same realizacije procesa v času (\(x(t)\)) enake statističnim lastnostim ansambla več realizacij dogodka \(x_k(t)\). Pravimo, da je posamezna realizacija procesa reprezentativna.
Primer 3
Opazujemo naključni proces \(x(t)\) z normalno porazdelitvijo verjetnosti (\(\mu = -4\), \(\sigma = 1\)), definiran v 25 časovnih točkah \(t = [0, 1, \dots, 24]\). Posnamemo ansambel \(N=50\) realizacij naključnega procesa.
Opazujmo razvoj srednje vrednosti in variance signala v času, \(\mu_x(t)\) in \(\sigma^2_x(t)\).
t = np.arange(25)
N = 50
mu = -4
sigma = 1
ansambel = []
for ponovitev in range(N):
ansambel.append(rng.normal(loc=mu, scale=sigma, size=len(t)))
ansambel = np.array(ansambel)
ansambel.shape # (50 realizacij, 25 "časovnih" točk)
(50, 25)
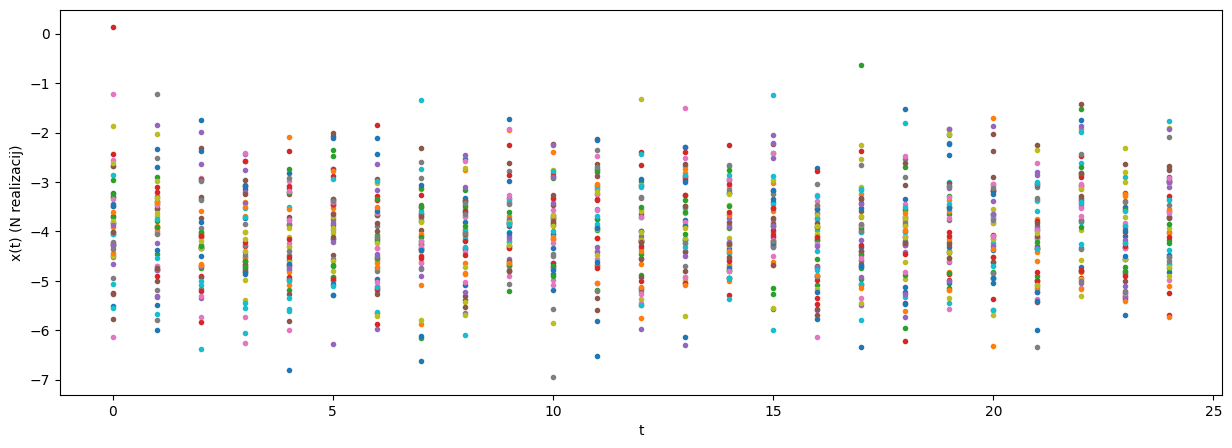
Srednja vrednost in varianca pri vsakem časovnem trenutku procesa (izračunana po osi realizacij):
mu_t = np.mean(ansambel, axis=0)
var_t = np.mean((ansambel-np.mean(ansambel, axis=0))**2, axis=0)
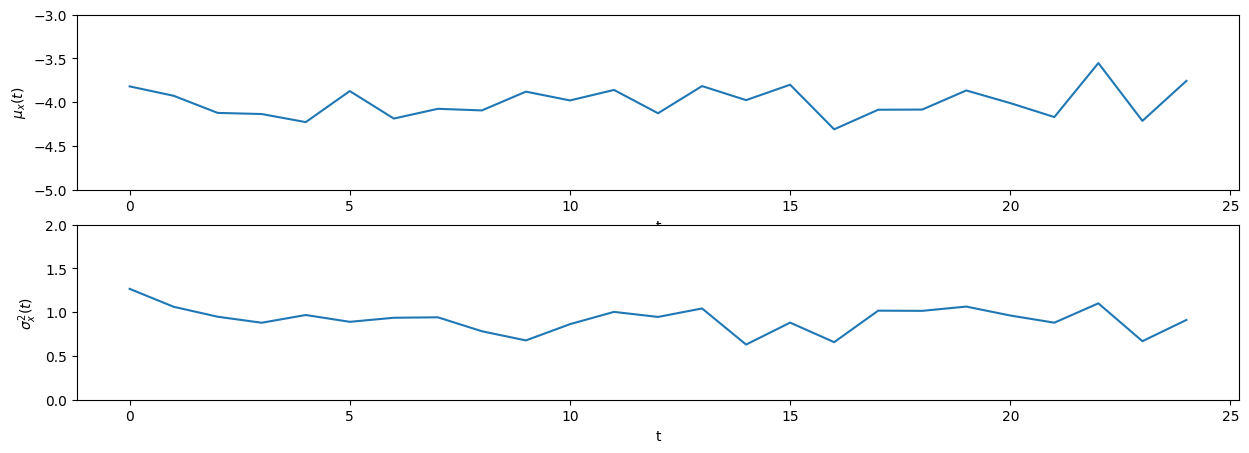
Ker se srednja vrednost in varianca naključnih realizacij v isti točki procesa s časom ne spreminjata, lahko sklepamo, da gre za stacionaren proces.
Srednja vrednost in varianca posameznih realizacij procesa (izračunana po osi časa):
mu_ansambel = np.mean(ansambel, axis=1)
var_ansambel = np.mean((ansambel-np.mean(ansambel, axis=1)[:, None])**2, axis=1)
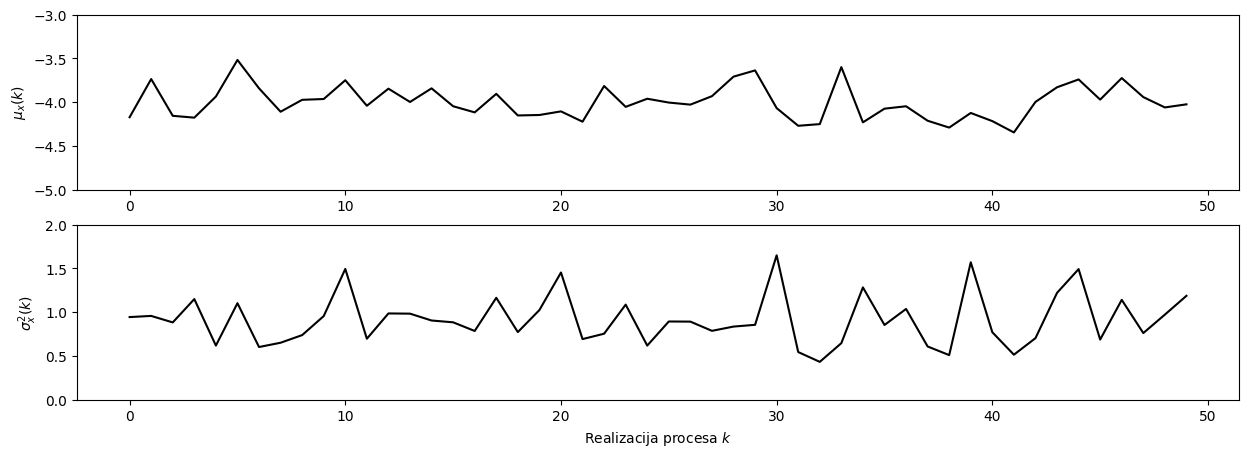
Ker se srednja vrednost in varianca naključnega procesa \(x(t)\) pri večkratni realizaciji ne spreminjata, in sta enaki \(\mu_x(t)\) in \(\sigma^2_x(t)\) pri posameznem času, lahko sklepamo, da gre za ergodičen proces.
Note
Avto-korelacijska funkcija \(R_{xx}(\tau)\) je definirana z:
in je enaka avto-kovariančni funkciji v primeru procesa z nično srednjo vrednostjo.
Note
Avto-spektralna gostota moči (PSD, Power Spectral Density) je Fourierova transformacija avtokorelacijske funkcije signala:
Za ergodičen proces jo lahko izračunamo kot:
Primer 4
Opazujemo naključni proces \(a(t)\), definiran z:
kjer je \(n(t)\) naključni šum z normalno porazdelitvijo (\(\mu=0\), \(\sigma=0.5\)).
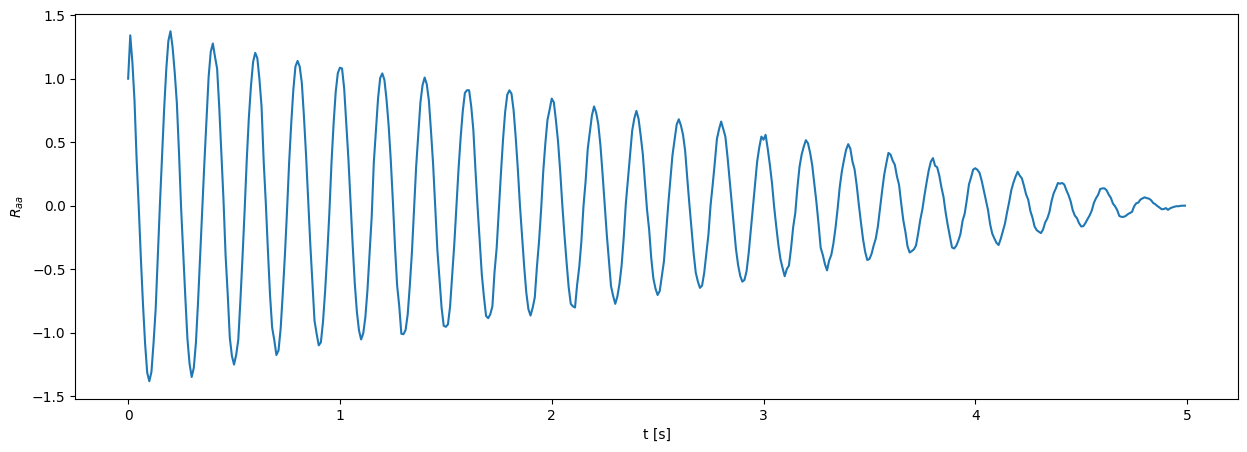
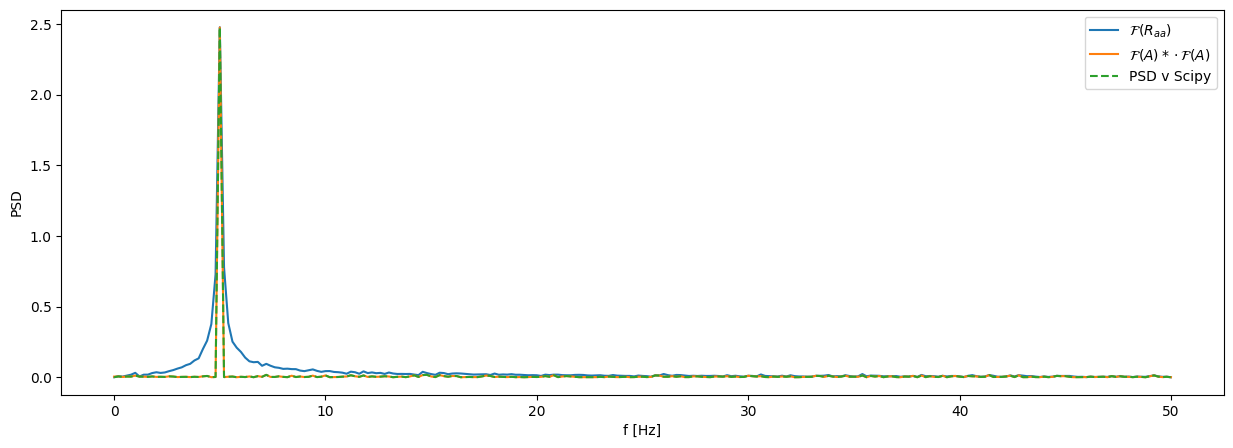
Opazujmo avtokorelacijsko funkcijo \(R_{aa}(t)\) in gostoto spektralne moči \(S_{aa}(f)\) signala \(a(t)\).
f = 5
T = 5
fs = 100
t = np.arange(fs*T) / fs
N = len(t)
a = np.sin(2*np.pi*f*t) + np.random.randn(len(t))*0.5
R_aa = np.correlate(a-np.mean(a), a-np.mean(a), mode='full') / N /np.std(a)**2 # Avtokorelacijska funkcija, normirana na varianco (R_aa[0] == 1.)
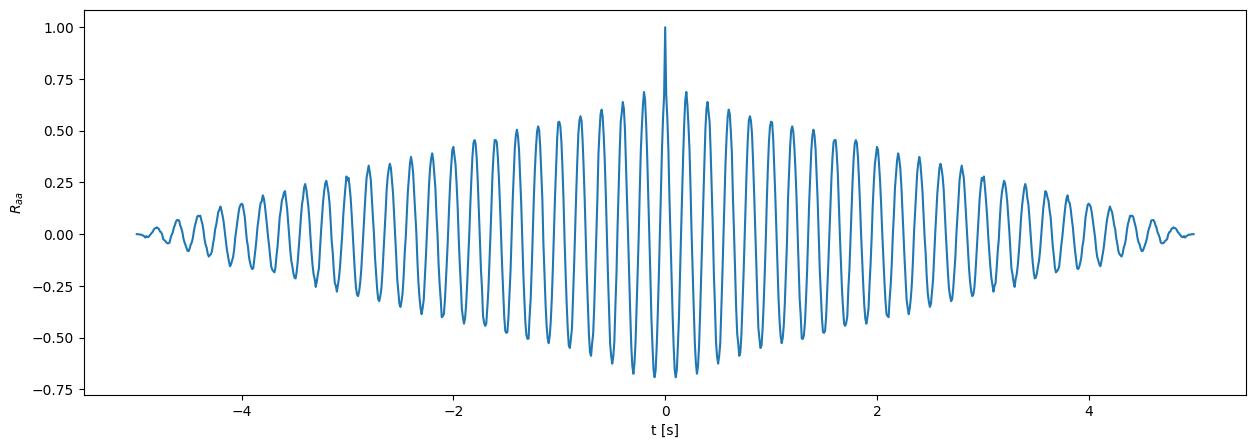
R_aa = R_aa[-len(a):] # Odstranimo del z negativnim časovnim zamikom, dobimo polje dolžine N.
R_aa[1:] *= 2 # Korigiramo energijo s faktorjem 2
G_aa_ = np.fft.rfft(R_aa) * 2 / fs # Ne delimo z N, ker smo normirali že R_aa.
G_aa_ *= np.std(a)**2 # Množimo z varianco, da dobimo nazaj fizikalne enote
A = np.fft.rfft(a) # Ne delimo z N, ker bomo normiranje opravili pri izračunu G_aa
freq = np.fft.rfftfreq(len(a), 1/fs)
G_aa = np.conj(A) * A * 2 / fs / N
Izračun PSD v Scipy:
from scipy.signal import welch
f_scipy, G_aa_scipy = welch(a, fs=fs, scaling='density', window=np.ones_like(a))
Parsevalov teorem:
a.var(), np.trapezoid(np.abs(G_aa), freq)
(np.float64(0.7052870815562242), np.float64(0.705721770631593))
Varianca meritve pri domači nalogi
Pri meritvah naključnega signala, generiranega z generatorjem signalov, boste tipično opazili veliko nižjo standardno deviacijo izmerjenih vrednosti od tiste, nastavljene na generatorju signala.
Generator signala generira naključni signal s širokopasovno porazdelitvijo (pasovna širina ~30 MHz). Ker ADC (Arduino) vzorči napetost v končnem časovnem oknu (čas ene konverzije ni neskončno kratek), deluje kot nizkopasovni filter - le del celotne moči generatorja pade znotraj tega pasu, izmerki so povprečje napetosti v času ADC pretvorbe.
Pojav je povezan s Parsevalovim teoremom, oceno pričakovane standardne deviacije tako izmerjenega signala prikazuje spodnji primer.
t_conversion = 104e-6 # približni čas trajanje enega samega izmerka A-D pretvornika [s]
BW_generator = 30e6 # frekvenčni pas generatorja signala [Hz] (SDG1032X)
sigma_set = 0.5 # primer nastavitve standardne deviacije na generatorju [V]
# Ker vzorčimo le ozek pas celotne pasovne širine, je pričakovana varianca sorazmerno nižja:
BW_measurement = (1 / t_conversion) / 2 # Nyquistova meja, glede na čas konverzije ADC
sigma_expected_measured = sigma_set * np.sqrt(BW_measurement / BW_generator)
print(f"Pričakovana sigma pri vzorčenju: {sigma_expected_measured:.4f} V")
Pričakovana sigma pri vzorčenju: 0.0063 V